Вступ
Процес вибору моделі для векторних представлень (embeddings) у RAG-системах в реальності зводиться до перегляду таблиць MTEB та вибору моделі з найвищим рейтингом. Але бенчмарки оцінюють моделі на загальних датасетах — не на ваших даних, не на вашому домені, не на ваших запитах.
Під час імплементації семантичного пошуку на AWS Bedrock, перед вами стоїть конкретне питання: яка embedding-модель краще працює саме з вашими даними? Amazon Titan Embeddings V2 чи Cohere Embed v3? Або щось інше? Відповідь залежить від домену та ваших даних — і її потрібно знайти емпірично.
Проблема в тому, що більшість порівнянь embedding-моделей зводяться до cosine similarity на кількох запитах та суб'єктивного висновку. Яким чином ми можемо статистично підтвердити нашу гіпотезу?
Ми задались пошуком відтворюваного механізму оцінки embedding-моделей, який можна застосувати до будь-якої пари моделей на будь-яких даних. Підхід складається з трьох компонентів:
- LLM-as-Judge — велика мовна модель (LLM) виступає суддею та оцінює якість результатів пошуку за структурованими критеріями (Zheng et al., 2023)
- Узагальнена лінійна модель (GLM) — формалізує зв'язок між моделлю та якістю результатів, з підбором linking function через AIC
- Тест відношення правдоподібності (likelihood ratio test) — визначає, чи є різниця між моделями статистично значущою
Як демонстрацію ми порівняли чотири моделі: Amazon Titan V1, V2 (AWS Bedrock) та all-MiniLM-L6-v2, bge-small-en-v1.5 (open-source). Але моделі лише приклад. Головне сам механізм, який ви зможете повторити у своєму проєкті.
Методи
Дані та моделі
Ми використали набір з 6000 продуктів у домені нутрієнтів, проіндексованих у pgvector. Для оцінки було створено 100 пошукових запитів різного типу, від конкретних назв продуктів до загальних категорій. Кожен запит обробляється чотирма embedding-моделями, двома хмарними (AWS Bedrock) та двома локальними (open-source):
AWS Bedrock (хмарні, managed):
- Amazon Titan Embeddings V1 (amazon.titan-embed-text-v1), перше покоління, 1536 dimensions
- Amazon Titan Embeddings V2 (amazon.titan-embed-text-v2:0), нове покоління, 1024 dimensions
Open-source (локальні, Transformers.js):
- all-MiniLM-L6-v2, найпопулярніша open-source embedding-модель, 384 dimensions
- bge-small-en-v1.5, модель від BAAI з високими показниками MTEB, 384 dimensions
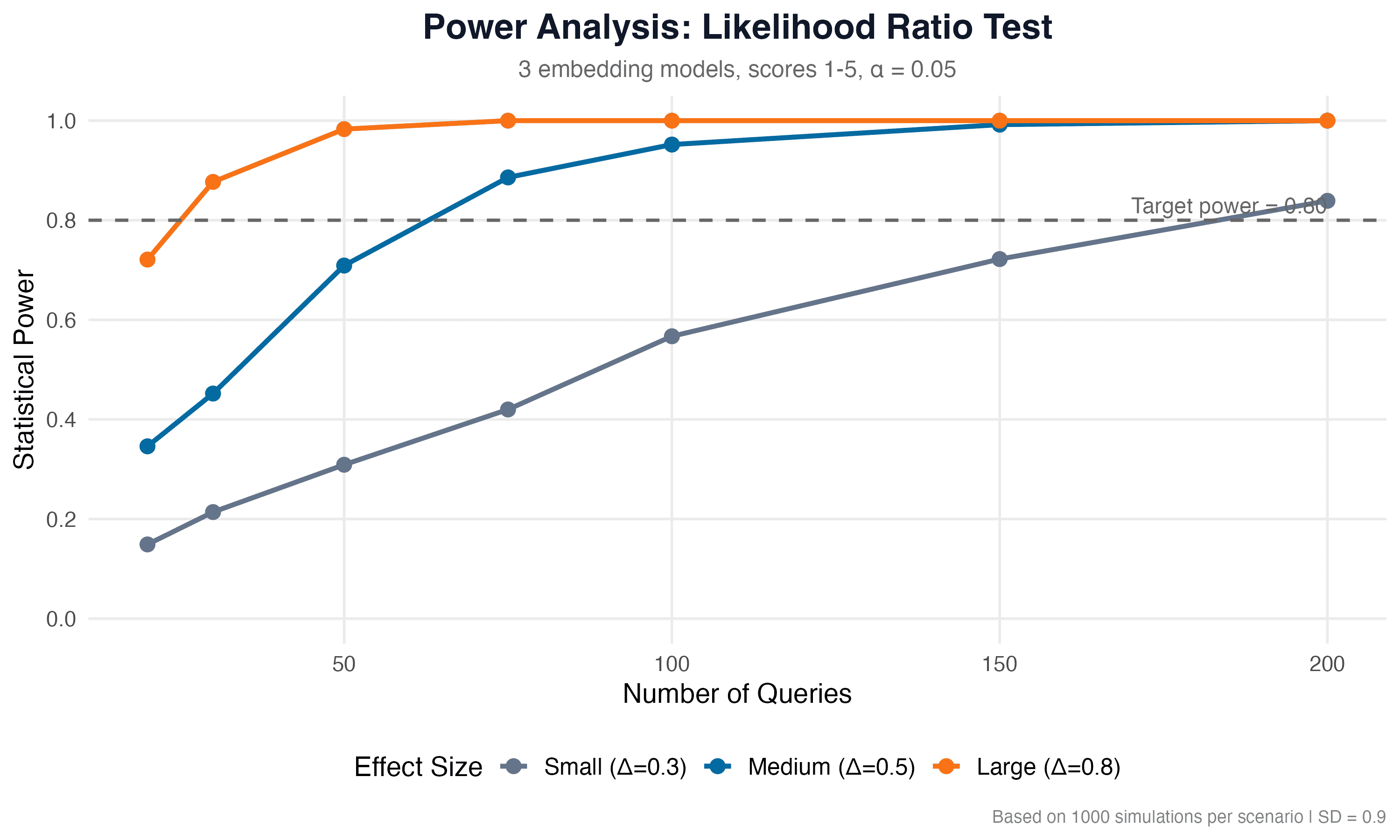
Результати пошуку — top-5 документів для кожного запиту — зберігаються для подальшої оцінки. Кількість запитів (100) було визначено на основі аналізу потужності (power analysis) з використанням пакетів lmtest та ggplot2 в R, що забезпечує статистичну потужність ≥ 0.80 для виявлення середніх та великих ефектів (α = 0.05).
LLM-as-Judge
Для оцінки якості результатів пошуку ми використали підхід LLM-as-Judge (Zheng et al., 2023). Claude оцінював кожну пару "запит — top-5 результатів" за шкалою від 1 до 5 за трьома критеріями:
- Релевантність (relevance) — наскільки результати відповідають запиту
- Порядок (ranking) — чи найбільш релевантні документи знаходяться вище
- Покриття (coverage) — чи охоплюють результати всі аспекти запиту
Для кожної комбінації "запит × модель" LLM генерував структуровану відповідь із оцінками та коротким обґрунтуванням. Це дало нам 400 спостережень (100 запитів × 4 моделі) з трьома числовими оцінками кожне.
Узагальнена лінійна модель (GLM)
Отримані оцінки ми аналізували за допомогою GLM в R з використанням пакетів stats, MASS та lmtest. Залежна змінна — оцінка якості (1-5), незалежна змінна — embedding-модель. Оскільки оцінки є ординальними, вибір linking function має значення. Ми тестували чотири варіанти — identity, log, inverse, logit — та обирали найкращий за критерієм Акаіке (AIC). Модель з найнижчим AIC найкраще описує зв'язок між embedding-моделлю та якістю пошуку.
Тест відношення правдоподібності (Likelihood Ratio Test)
Для перевірки статистичної значущості різниці між моделями ми використали likelihood ratio test з пакету lmtest. Порівнювали дві моделі: нульову (оцінка не залежить від embedding-моделі) та альтернативну (embedding-модель впливає на оцінку). Якщо p-value < 0.05, ми маємо статистичні підстави стверджувати, що вибір embedding-моделі має значущий вплив на якість результатів пошуку.
Візуалізація
Результати ми візуалізували в R за допомогою ggplot2. Для кожного критерію (релевантність, порядок, покриття) побудували:
- Box plot — розподіл оцінок по моделях
- Bar plot з довірчими інтервалами — середні оцінки та 95% CI
- Heatmap — порівняння моделей по всіх критеріях одночасно
Кожен графік супроводжується p-value з likelihood ratio test.
Результати
Аналіз потужності
Перед збором даних ми провели simulation-based power analysis, щоб визначити необхідну кількість запитів. Для середнього ефекту (Δ = 0.5) 100 запитів забезпечують потужність 0.952, для великого ефекту (Δ = 0.8) потужність досягає 1.0. Це означає, що 100 запитів достатньо для виявлення практично значущих відмінностей між моделями при α = 0.05.
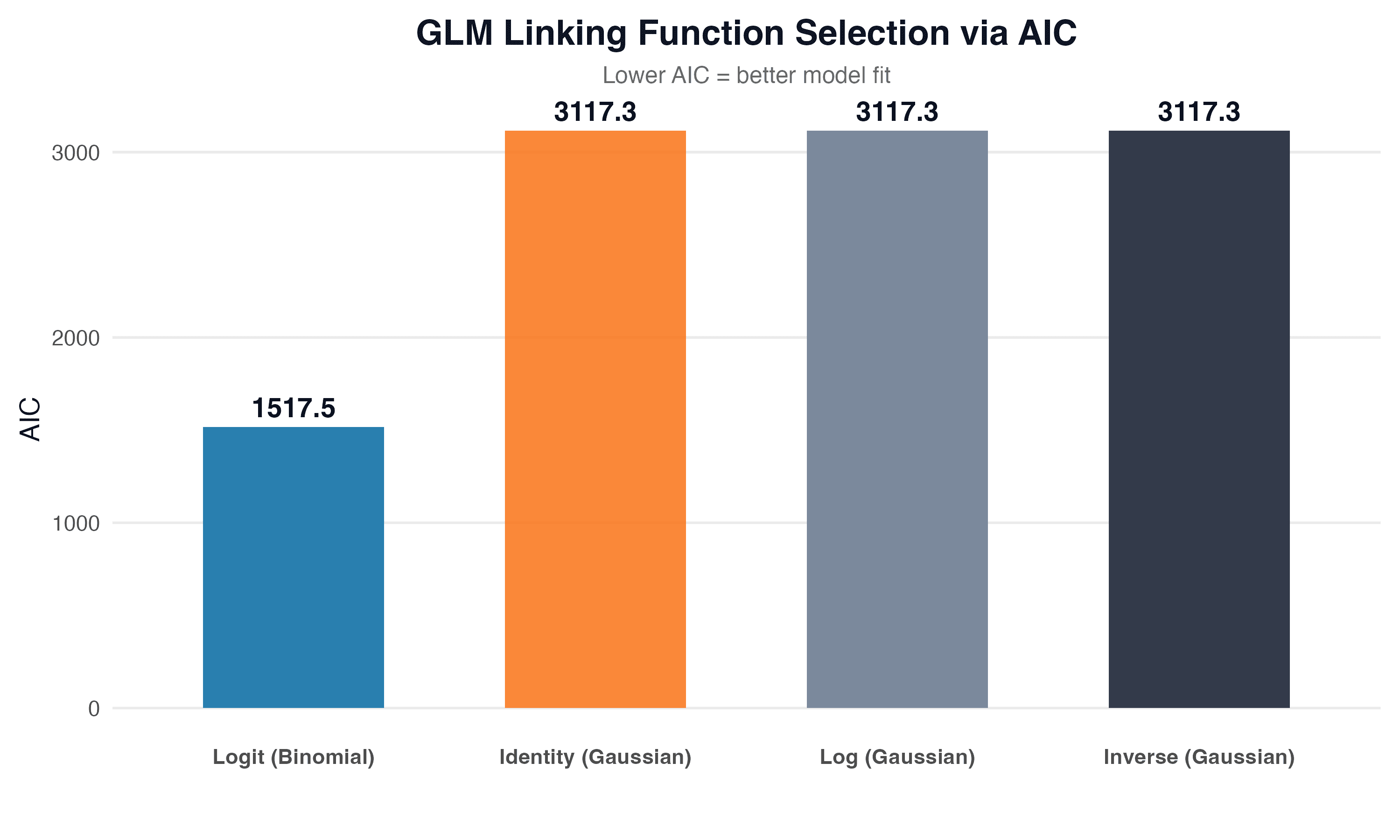
Підбір linking function
Ми тестували чотири linking functions для GLM та обирали найкращу за критерієм Акаіке (AIC):
| Linking function | AIC |
|---|---|
| Identity (Gaussian) | 3117.3 |
| Log (Gaussian) | 3117.3 |
| Inverse (Gaussian) | 3117.3 |
| Logit (Binomial) | 1517.5 |
Logit (Binomial) отримала найнижчий AIC з великим відривом (1517.5 проти 3117.3), що вказує на значно кращу відповідність моделі до даних. Це логічно: оцінки обмежені діапазоном 1-5, і logit link коректно моделює таку обмежену залежну змінну.
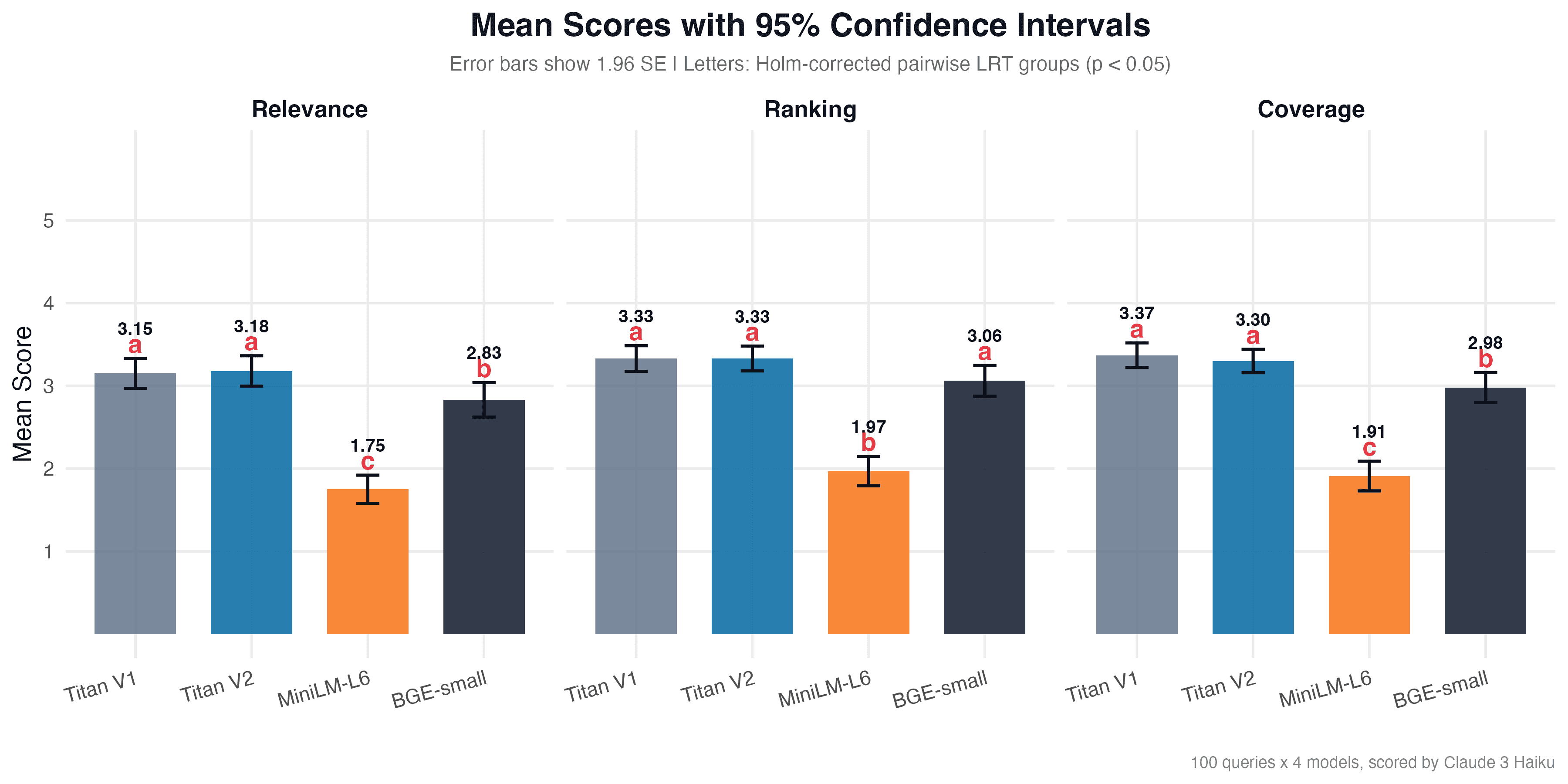
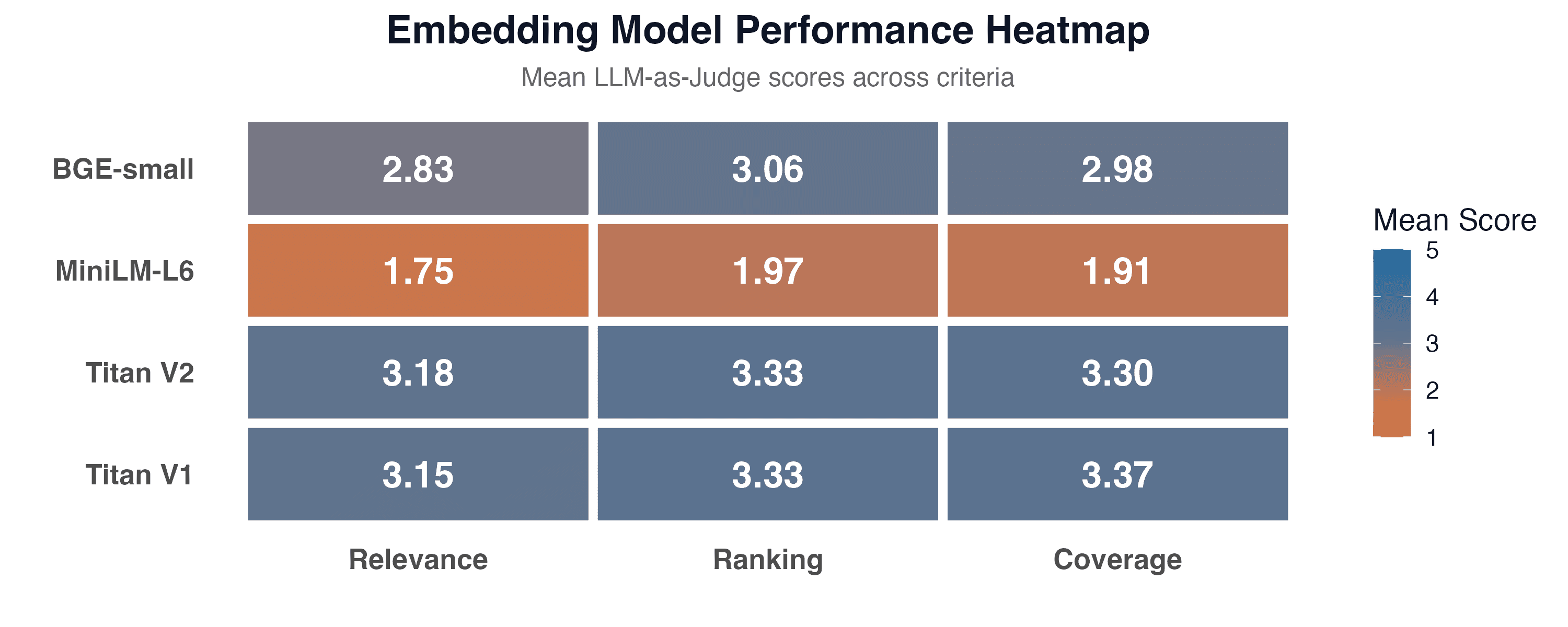
Описова статистика
Середні оцінки (шкала 1-5) по кожному критерію:
| Модель | Релевантність | Порядок | Покриття |
|---|---|---|---|
| Titan V1 | 3.15 (SD = 0.93) | 3.33 (SD = 0.79) | 3.37 (SD = 0.76) |
| Titan V2 | 3.18 (SD = 0.94) | 3.33 (SD = 0.77) | 3.30 (SD = 0.72) |
| BGE-small | 2.83 (SD = 1.06) | 3.06 (SD = 0.95) | 2.98 (SD = 0.92) |
| MiniLM-L6 | 1.75 (SD = 0.87) | 1.97 (SD = 0.90) | 1.91 (SD = 0.91) |
Titan V1 та V2 показали найвищі середні оцінки по всіх критеріях. BGE-small трохи поступається, але залишається в діапазоні 2.8-3.1. MiniLM-L6 значно відстає з оцінками 1.75-1.97.
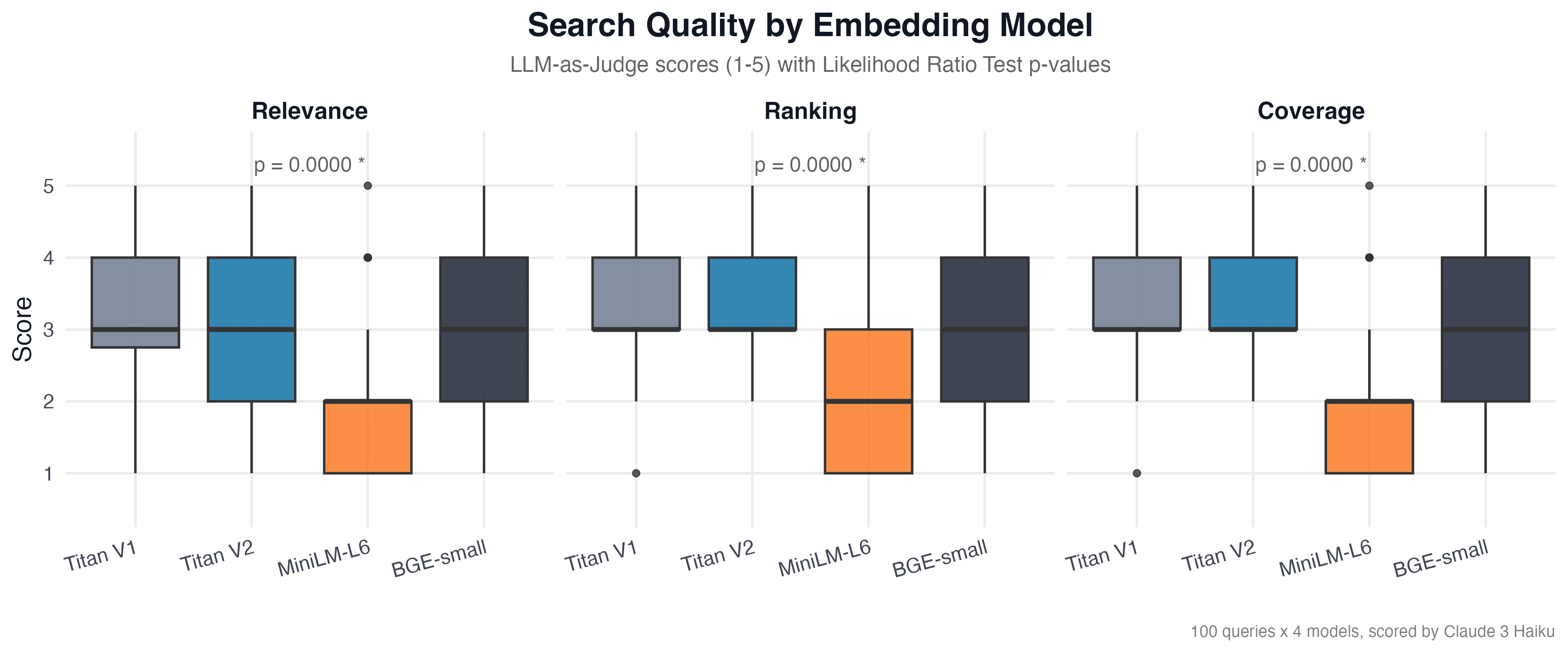
Likelihood Ratio Test
Для кожного критерію ми порівняли нульову модель (оцінка не залежить від embedding-моделі) та альтернативну (embedding-модель впливає на оцінку):
| Критерій | χ² | p-value | Значущість |
|---|---|---|---|
| Релевантність | 127.8 | 1.60 × 10⁻²⁷ | *** |
| Порядок | 143.8 | 5.63 × 10⁻³¹ | *** |
| Покриття | 161.7 | 7.99 × 10⁻³⁵ | *** |
| Загальний | 428.7 | 1.33 × 10⁻⁹² | *** |
Всі p-values значно менші за α = 0.05. Вибір embedding-моделі має статистично значущий вплив на якість пошуку за всіма критеріями. Загальний тест (χ² = 428.7, p = 1.33 × 10⁻⁹²) підтверджує, що різниця між моделями не є випадковою.
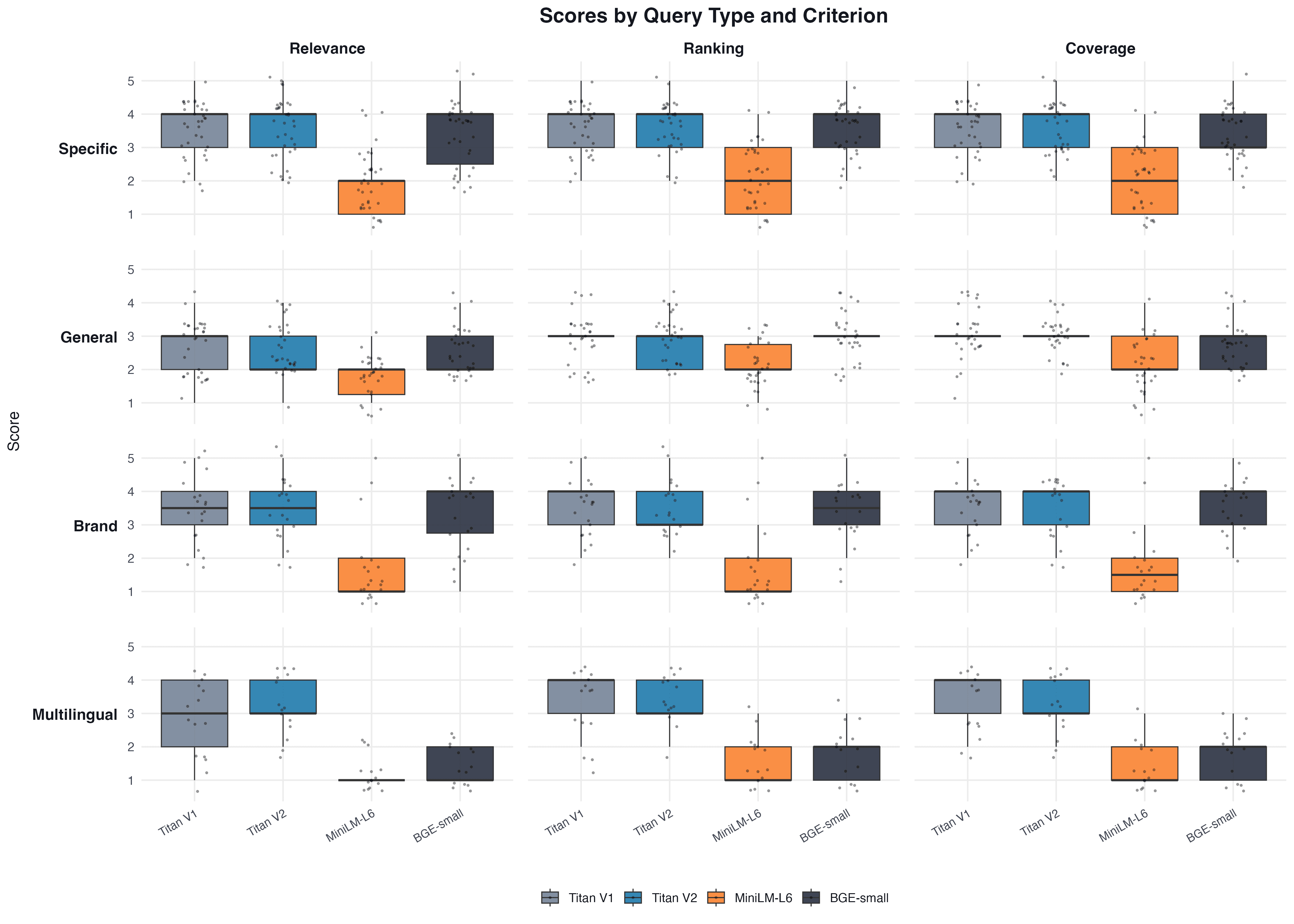
Порівняння по типах запитів
Ми також проаналізували результати в розрізі типів запитів (specific, general, brand, multilingual). Результати показують, що різниця між моделями зберігається незалежно від типу запиту, хоча амплітуда відрізняється.
Дискусія
Omnibus likelihood ratio test показав, що вибір embedding-моделі має статистично значущий вплив на якість пошуку (χ² = 428.7, p = 1.33 × 10⁻⁹²). Але сам по собі цей результат не відповідає на питання "які саме моделі відрізняються". Post-hoc попарні порівняння з корекцією Холма дають конкретну картину: Titan V1 та V2 не відрізняються між собою (p = 0.82 для релевантності, p = 1.0 для порядку, p = 0.50 для покриття), тоді як MiniLM-L6 значущо поступається всім іншим моделям по кожному критерію (всі p < 10⁻¹³). BGE-small займає проміжну позицію: для ranking вона статистично не відрізняється від Titans (p_adj = 0.08), але для relevance та coverage різниця значуща (p_adj < 0.05).
Важливо зазначити обмеження підходу. LLM-as-Judge має власні упередження (Zheng et al., 2023): Claude може систематично завищувати або занижувати оцінки. Однак для відносного порівняння між моделями ці упередження є константними і не впливають на валідність likelihood ratio test. Результати також залежать від домену: модель, яка працює на нутрієнтах, може поступитись на юридичних або медичних текстах. Аналіз по типах запитів показав, що різниця між моделями зберігається для specific, general, brand та multilingual запитів, хоча амплітуда відрізняється. MiniLM-L6, як монолінгвальна модель, очікувано показала найгірші результати на multilingual запитах (медіана = 1 для релевантності).
Практична цінність механізму в його відтворюваності. Весь pipeline (генерація embeddings, LLM-as-Judge, GLM з підбором linking function через AIC, post-hoc попарні порівняння з корекцією Холма) можна запустити на нових даних за годину і отримати статистично обґрунтовану відповідь замість суб'єктивного "ця модель здається кращою".
Висновок
Ми побудували відтворюваний механізм оцінки embedding-моделей та протестували його на чотирьох моделях (Amazon Titan V1, V2, all-MiniLM-L6-v2, bge-small-en-v1.5) з використанням 6000 продуктів у домені нутрієнтів. Механізм включає: power analysis для визначення кількості запитів, LLM-as-Judge для автоматичної оцінки, підбір linking function через AIC (logit виявився оптимальним), omnibus LRT та post-hoc попарні порівняння з корекцією Холма.
Результати показали три чіткі групи: Titan V1/V2 (група "a", середні оцінки 3.15-3.37), BGE-small (група "b", 2.83-3.06) та MiniLM-L6 (група "c", 1.75-1.97). Titan V1 та V2 показали статистично ідентичні результати (p = 0.82-1.0 по всіх критеріях), хоча V2 позиціонується як нове покоління з більшими можливостями та вищою ціною. Для задач семантичного пошуку в e-commerce домені різниця між поколіннями не виявлена, що дозволяє обрати дешевший варіант без втрати якості.
Головний результат цієї роботи не в рейтингу моделей, а в самому механізмі. Ви можете замінити моделі, дані та критерії оцінки на свої і отримати статистично обґрунтовану відповідь для вашого домену.
Джерела
- Muennighoff, N. et al. (2023). "MTEB: Massive Text Embedding Benchmark." EACL 2023. doi:10.18653/v1/2023.eacl-main.148
- Zheng, L. et al. (2023). "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena." NeurIPS 2023. arXiv:2306.05685
- Saad-Falcon, J. et al. (2024). "ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems." NAACL 2024. doi:10.18653/v1/2024.naacl-long.20